注:近日,金电联行首席科学家曹鸿强在天堂硅谷信息技术闭门会上做了精彩发言,以下根据其讲话实录整理而成。

感谢主办机构。很高兴有这个机会,和大家分享金电联行在大数据领域的一些观点和做法。
首先介绍一下公司的情况。金电联行有两个显著标签:一是国内大数据行业领军企业之一。公司成立于2007年,是国内最早涉足大数据行业的高新技术企业,经过多年发展,在金融大数据、政务大数据、产业大数据的部分细分领域已经位居全国领先地位。二是国内信用建设主导企业之一。我们是国内最早运用大数据技术开展信用体系建设的企业,是中国人民银行首批备案的全国性企业征信机构、北京征信机构总经理联席会主席单位;是国家发改委综合信用服务试点机构、第三方评估机构;是工信部、科技部等主管单位认定的信用体系建设和中小微企业信用融资评价机构;国家公共信用信息中心第一批可为信用修复申请人出具信用报告的信用服务机构。
作为一家大数据企业,金电联行有一个基本观点:大数据正在推动流程化系统向决策支持系统转变。在IT领域,如果说过去二三十年是流程化系统占据主导地位,那么未来二三十年一定是决策支持系统占据主导地位,要用数据说话,要让数据说话。
因此,金电联行将核心业务能力定位为帮助客户实现决策支持系统。经过在金融、政务、产业等市场十多年领域的技术积累,我们建立了覆盖大数据价值变现全链条的五层架构(如下图所示):最底层是大数据输入输出控制器和大数据基础平台,其中前者实现大数据的内外交换及其控制,例如安全、计费等,类似计算机的南桥芯片;后者是大数据存储、处理、分析的基础设施,类似计算机的主板。倒数第二层是大数据管理器,实现了大数据的数据管控,例如数据标准、元数据、数据质量、数据谱系等,类似计算机的北桥芯片。中间一层是大数据中央处理器,即针对大数据的数据工厂平台,实现规模化的大数据加工处理,类似计算机的CPU芯片;再往上是大数据通用AI处理器,即针对大数据的数据科学平台,实现规模化的大数据分析挖掘,类似计算机的GPU芯片。最上面一层是大数据专用AI处理器,固化业务专家的方法论和知识经验,实现面向特定领域的大数据分析挖掘,类似计算机的FPGA芯片。这五层架构作为一个整体,支撑信贷风控、精准营销、社会治理、企业征信、智能定价、预测性维护等各种具体大数据决策支持应用,类似计算机作为一个整体支撑各种软件应用。当然,有可能五层架构的某个部分是客户自研的,或者是友商的,例如大数据基础平台。我们的五层架构是开放的,有对外的兼容性。金电联行大概就是这样一个产品和技术架构,我们认为,这个架构是建设决策支持系统(包括开发和运维的全生命周期)的一条有效路径。
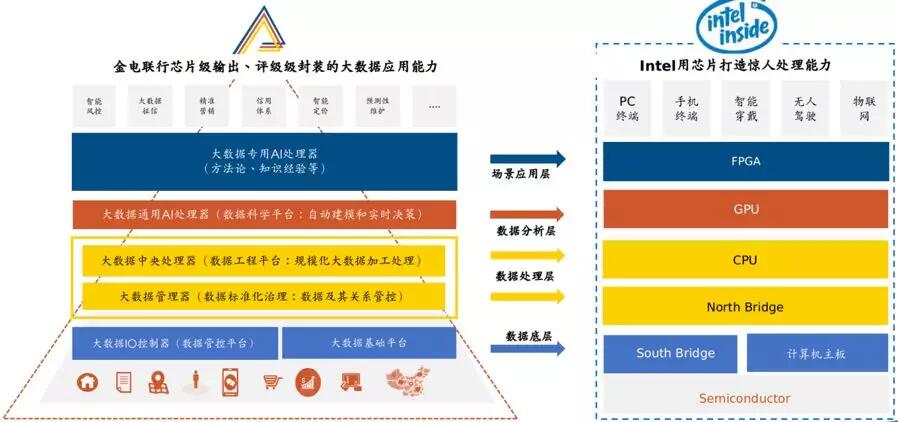
在二十多年前读书的时候,我曾经学过一门课程,叫计算机辅助软件工程,英文缩写是CASE。如果大家都认可,决策支持系统是一种特殊的IT系统,大数据处理和分析软件是一种特殊的软件,那么我们的五层架构,特别是数据工程平台和数据科学平台,不就是一种CASE工具、一种针对大数据软件开发的特殊CASE工具么?这种特殊的CASE工具,目标是让计算机帮助人更优质、更高效地开发大数据应用这种特殊的软件。如何帮助人?关键的两点:一是智能化、二是工程化。所谓智能化,就是在工具中固化人的方法论和知识经验,就是让工具使用最先进、最智能的模型算法,就是让工具的数据和知识产出更符合人的认知方式和认知习惯,使得数据处理、数据分析更加高效。所谓工程化,就是大数据应用的开发维护要遵循软件工程的基本原理,工具要支持设计和实现的一致性,工具要支持配置管理、软件测试、持续集成等,软件过程和软件资产要受管受控,使得大数据应用软件更加优质。
融合了智能化和工程化的五层架构整合到一块,为金电联行实现核心竞争力从技术上提供了有力支撑。其效果就是:可以帮助客户低成本、高质量地建设决策支持系统。低成本是由于所有核心和基础的软件构件开发工作都提前完成了,有各种预制件,包括实现数据处理的预制件、实现数据建模的预制件、实现数据展示的预制件等等,只是根据客户需求做不同的编排组合,编码层级的软件开发工作量大大减少,省人省时。高质量是由于大部分功能和流程都是预制件,而且是抽象层级很高的预制件,软件质量在预制过程中已经确认,所以整个系统的质量很高。比方说我们给某个政府机构做一个重点企业监测系统,传统建设方式要两三个月,可我们使用五层架构,编排预制件,两三周就高质量交付了,获得客户好评。
事实上,我们给金融机构、政府、产业等客户交付的各种决策支持系统,都是采用同样的五层架构,只不过是不同的业务需求、不同的数据输入、不同预制件的不同编排组合、不同的模型输出、不同的用户界面。这就类似于收音机的生产方式变革,最早是电子管的,后来是晶体管的,再后来是集成电路的,现在是智能手机里面的一个应用程序,也被叫做软件无线电;当然智能手机里还有其他程序。决策支持系统建设也是如此,我们开始时模块化,后来是纵向封装,现在是五层架构。我们称其为大数据应用能力的芯片级输出、平台级封装。正是基于这种能力,金电联行可以随时切换应用场景,以一套产品和技术体系架构,低成本和高质量地满足金融、政务、产业等不同领域,不同客户的不同需求。这样一种系统建设模式变化是革命性的,为客户创造了价值,得到了市场认可。

下面在五层架构框架下,谈谈数据建模和数据科学平台,它们是大数据应用能够“从数据挖掘知识,使用知识创造价值”的关键环节所在。
所谓数据建模,就是从数据中探寻客观世界的真理。从本质上讲,数据建模体现了一种潜藏在人性深处的驾驭数据的需要,或者说是本能:从积极方面讲,人类通过数据建模满足好奇心;从消极方面讲,人类通过数据建模寻求安全感。具体到我们的客户,他们期望能够通过数据建模,洞察业务特点规律,以支撑决策、防范风险。具体而言:
决策是数据建模的目标。可以从两个维度考察决策的特征:一个维度是决策的复杂性,一个维度是决策的风险性。决策的复杂性包括:决策的环境是否确定、决策的信息是否完备、决策的目标是否单一、决策的时间是否充足等等,这些决定了决策的难易程度。单从环境是否确定、信息是否完备而言,AlphaGO做的是简单决策,股票投资做的是复杂决策。决策的风险可以分为低、中、高,它代表了决策的利害相关程度,例如投资是高风险决策,外部环境越不确定、投资额越大风险越大,当然收益也越大;相对而言,商品推荐是低风险决策。
数据是数据建模的输入。同样可以从两个维度考察数据的特征:一个维度是数据规模,一个维度是数据质量。数据规模可以分为小、中、大:小规模数据单机内存就可以容纳;中规模数据单机硬盘或者小规模计算机集群内存可以容纳;大规模数据大规模计算机集群内存和硬盘才可以容纳。数据质量包括数据的完整性、数据的准确性、数据的结构化程度、数据的时效性、数据的持续性等等,它们决定了数据加工处理的难易程度。
模型是数据建模的输出。可以从多个维度考察模型的特征,包括模型的准确性、模型的可靠性、模型的安全性(即抗攻击性)、模型的可解释性、模型的时效性、模型的经济性、模型的公平性等。其中最重要的两个维度是模型的准确性和模型的可解释性,简而言之,就是既要知其然、也要知其所以然。
金电联行的客群主要集中于金融机构、政府部门和大型企业,我们要帮助他们构建基于大数据的决策支持系统。对于这些客户,从数据而言,通常是中大规模、中低质量;从决策而言,通常是中高风险、复杂决策;从模型而言,通常要兼顾准确性和可解释性。需要特别强调,这些客户风险厌恶程度相对偏高。心理学有个著名的前景理论,讲的是人都有所谓的“损失厌恶性”。这些客户尤其如此。由于决策的利害相关性,永远是合规第一、安全第一、可控第一,可以不使用大数据模型、不获得大数据模型带来的收益,但是不可以因为使用大数据模型,而产生不可预测的风险,即便是相对小的发生概率。大数据模型必须要有助于防范风险,而不是带来未知风险。在很多应用场景下,客户不会接受由成千上万特征和成千上万规则构成的黑盒机器学习模型,必须把黑盒模型打开成白盒模型。客户要的是:在业务知识规律约束下的大数据模型,也就是可以把控的大数据模型,当然成本要尽可能低、性价比要尽可能高。这就是我们面对的市场。
基于这样的市场认知,金电联行研发了“全智”数据科学平台,帮助客户低成本、高质量、工程化地构建“既知其然、也知其所以然”的大数据模型。除了常规数据科学平台的共性之外,“全智”数据科学平台的特色在于实践了以人为本、人机融合的建模理念,既依靠人,又服务人。所谓依靠人,就是通过知识图谱、因果推断、机器教学等技术途径,在建模平台中固化业务专家以及建模专家的方法论和知识经验,同时结合最先进的自动建模算法,使得建模过程更规范、更高效、更智能、更经济。所谓服务人,就是使用模型可视化、白盒模型构建、黑盒模型解释等技术途径,使得建模成果能够以方便人理解使用的方式输出,不仅向人输出模型,而且向人输出模型解释,以帮助人实现业务洞察。实践表明,“全智”数据科学平台的技术理念是务实的,适合了市场需求,得到了客户肯定,对于大数据和人工智能技术在各领域、各行业落地实施,发挥了技术引领和推动的作用。
谢谢大家!